目标检测模型中的基本结构
在开始实现目标检测模型之前,我们先来回顾下深度学习中的一些基本结构。
这一部分,主要是让大家从比较感性的层面去知道每个结构的作用是什么,以及如何去使用这些结构。
至于更深层的理论,不在这里赘述,不然会使得教程比较乏味。
这一部分结束后,我们会利用这些基本结构,来实现一个简单的目标检测模型。
这一部分只讲解了一些最基本的结构,除了这些,还有很多常用的结构,我们会在后面部分慢慢讲解。
这些最基本的结构,就足以让我们完成一个简单的目标检测模型。
更多的结构,我们会在后面应用到网络中,看看他们是如何工作的,以及如何提高检测性能的。
如果把整个深度学习任务分成几个部分,大概可以分为:
- 数据集。明确任务的输入和输出形式,通俗点说就是明确数据集的标注形式。(数据集,上一个章节已经着重讲过了目标检测的数据集)
- 模型。根据任务的输入和输出形式,来设计网络模型。
- 损失函数。衡量模型输出和真实值之间的差距。
- 优化器。制定优化方案来训练模型,让模型的输出接近真实值。
我们简单来回顾下这部分。从感性上进行认识。组建深度学习模型就像拼积木一样,我们需要把每个积木的功能有个大概了解后,就可以开始拼积木了。
为了章节优化,我们在这一部分只介绍最基础的网络结构,然后我们用这个最基础的网络模型来搭建我们第一个目标检测模型, 之后,我们再介绍一些更高级的网络结构,并测试下这个高级的网络结构是否能够提高我们的模型性能。
我们来对深度学习模型整个操作过程来打个比方,给大家一个感性的认识。知道每个部分的作用是什么。
就拿
网络模型
二维卷积 (Conv2D)
二维卷积,是 计算机视觉 或者 图像领域中最重要的一种网络结构。
一般,我们是这样理解 二维卷积 的作用:用来从图像中提取任务所需要的特征信息,简单来说,就是提取特征。
二维卷积,就是对二维图像进行卷积操作。我们知道图像是有横向和纵向(X和Y轴)的,所以图像是二维的。
二维很好理解,而要理解卷积的话。我们要知道 卷积 是一种操作,类似于 加减乘除这种,是一种规定的运算规则。 而要进行卷积操作的时候,需要借助到 卷积核 这个东西,更专业的术语,应该叫做 算子。
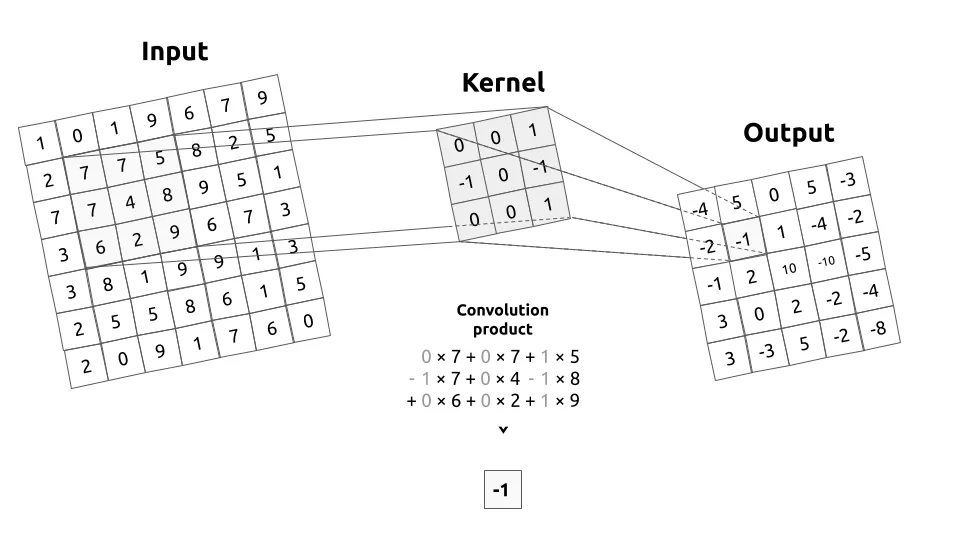
我们在利用二维卷积来构成深度学习模型的时��候,一开始,我们会给卷积核(Kernel)赋予
卷积是图像处理中的非常重要的操作。注意,只是在图像领域中哦。
介绍下 Conv2D各个参数的含义。
池化
池化,主要目的是为了较少模型的参数量,让模型更加容易进行收敛。 同时,通过一些操作来弱化一些非主要信息,
非线性激活
要理解 非线性激活,我们需要首先理解什么是线性。
这个时候,我们就要拿出我们以前学习的 y=kx+b。这就是一个线性
非线性激活,就是在模型中引入线性激活。
总而言之,大家可以把每个网络模型看成大量参数的黑盒子。其中的大量参数会对输入数据进行各种各样的处理,然后最终产生一个输出。
损失函数
损失函数,就是制定一些规则来平衡 模型输出 和 正确输出 之间的差距。
就像我们考试打分一样,制定一些打分标准。
下面,我们主要来介绍一些常见的损失函数,也就是打分规则。
就像我们试卷一样,不同的题目(任务)有着不同的打分规则。
均方误差损失
均方误差损失的规则比较简单�。比如说我们现在模型有3个输出,分别为 X1, X2, X3。
交叉熵损失
优化器
优化器,